Standards for branching and merging
This document results from the discussion of the 2023-03-01 all-RSEs internal meeting.
Branching workflow
In all our repositories, new code should be added in a feature branch before being submitted as a pull request (PR).
Two development strategies are common:
- Git flow where you have 2 long-running branches: the stable
mainbranch, and the unstabledevelopmentbranch; and many feature branches originating from and being merged into development - GitHub Flow: A simpler feature branch flow, where
mainis the only long-running branch, hosting the development version; and many feature branches originating from and being merged into it. In this flow, stable versions are contained in releases (possibly on CRAN in the case of R packages)
The R community in general sticks with a simple feature branch flow, and doesn’t use a development branch. Most developers and users assume that the main GitHub version can be somewhat unstable and that stable releases are on CRAN.
| GitHub Flow | Git Flow | |
|---|---|---|
| feature | 1 long-running branch | 2 long-running branches |
| characteristic |
|
|
| installation instructions | The real package can be installed from CRAN with: | The real package can be installed from CRAN with: install.packages("real") | install.packages("real") You can also choose to install the development version of real from GitHub: | You can also choose to install the development version of real from GitHub: pak::pak("epiverse-trace/real") | pak::pak("epiverse-trace/real@dev") | |
|
use of the pkgdown development mode to build two websites:
|
in the |
A custom
|
At the time of writing this chapter, the @epiverse-trace/lac team team uses a branching process inspired from Git Flow and the @epiverse-trace/lshtm-mrcg team uses a workflow inspired from the GitHub Flow.
Avoid long feature branches
The common feature of both workflows is that new code is added in a feature branch before being submitted as a pull request (PR).
Each branch, and each pull request, should focus on a single feature. This can, for example, be achieved by creating one branch (and subsequently a pull request) per issue. Keep your branches focused on single small features/changes. Make sure to tie individual units of changes in one or more files in a commit. This will lead to small manageable branches and pull requests and ease the code review process.
If you want to contribute multiple unrelated changes to the codebase, please open multiple pull requests.
It is advised to use short branches because long branches are:
- More difficult and time consuming to review
- More difficult to work on
- More likely to result in conflicts
- In contradiction with the agile strategy we adopted
Requiring passing tests
We have a suite of automated tests running in PR. In general, we require tests to pass before merging the branch.
However, in the rare case of an unexpected, unrelated bug popping up in a PR, it may sometimes be acceptable to merge a branch with failing tests (provided the tests don’t point out an actual bug!) to keep the PR focused on a specific unit of changes.
Another, preferred strategy, would be to open a new PR, fix the tests, and then rebase the previous branch on top of main / develop where tests are now passing.
Merging pull requests: “merge commits” vs “squash and merge” vs “rebase and merge”
GitHub currently has 3 pull request merge mechanisms:
- Create a merge commit
- Squash and merge
- Rebase and merge
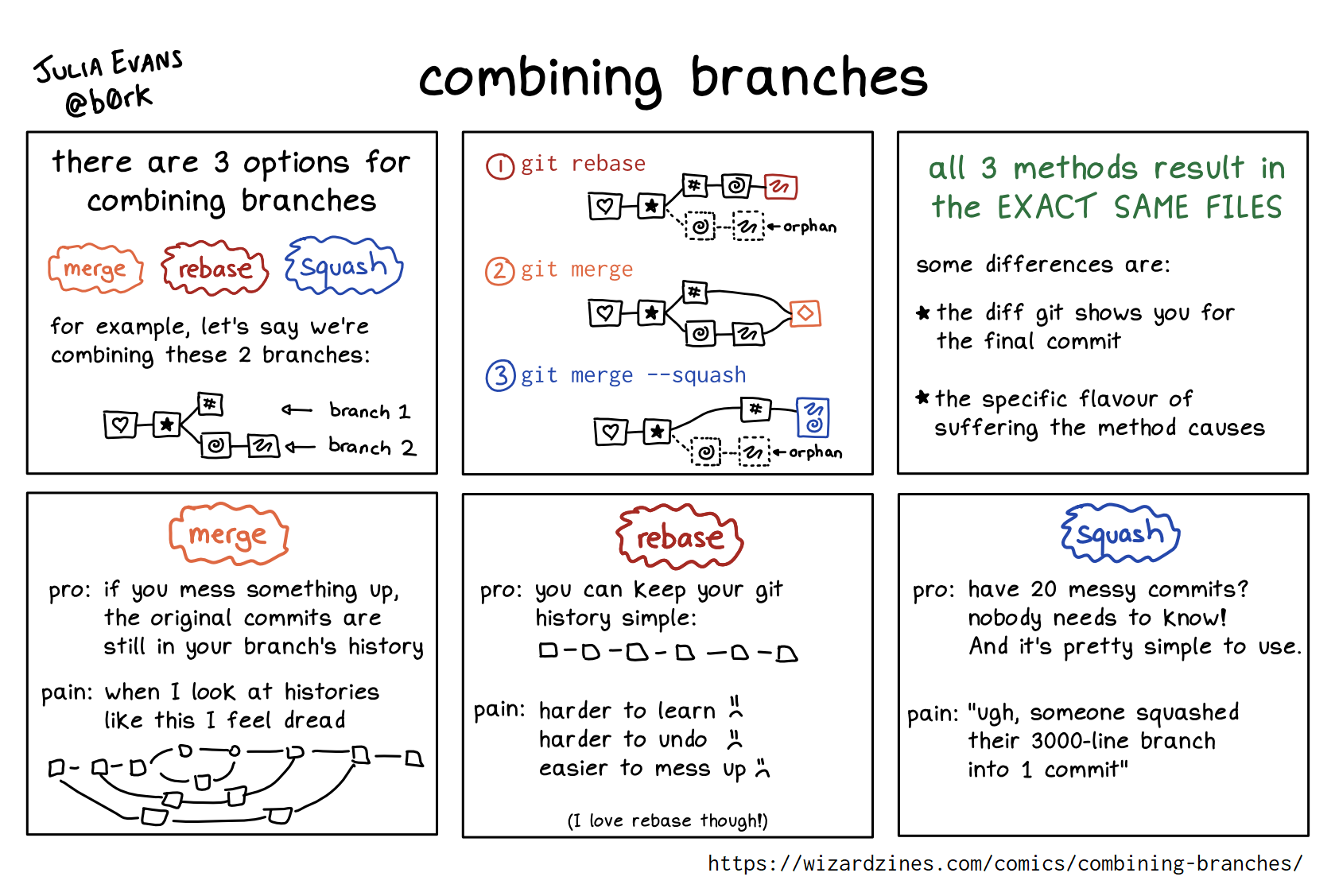
The historical option ‘merge commits’ presents severe drawbacks, such as creating a heavily non-linear history, which is extremely difficult to read. Notably, it is very difficult to browse & understand a git history with merge commits in GitHub web interface. Yet, git history is a very precious source of information in older packages to inform new maintainers about the reasons behind some choices by old maintainers. For related reasons, merge commits can sometimes create flat out unintelligible diffs in pull requests.
Because of this, we have disabled merge commits in our repositories. Instead, we rely on either ‘rebase and merge’ (preferred option) if commits are grouped logically and have clear error messages, or ‘squash and merge’ if we don’t want to keep the commit history (as a last resort; if the commit history is too messy and impossible to clean, or if there is a merge commit in the history). If necessary and in order to make a ‘rebase’ rather than a ‘squash’, the PR history can be rewritten & cleaned using a command-line interactive git rebase, and squashing, re-ordering, rewording, etc. as necessary and as described in this blog post.
Deleting merged branches
To avoid confusing situations with diverging histories, we prefer to delete branches. The setting “auto-delete branches from merged PR” should be activated on all our repositories.
We also encourage external contributors to follow the same tip in their own forks, where we cannot auto-delete branches.
If you would like to add your input on this chapter or would like to know more about the reasons behind our choices, please checkout the related GitHub issue.